How to Configure Your dbt Repository (One or Many)?

At dbt Labs, as more folks adopt dbt, we have started to see more and more use cases that push the boundaries of our established best practices. This is especially true to those adopting dbt in the enterprise space.
After two years of helping companies from 20-10,000+ employees implement dbt & dbt Cloud, the below is my best attempt to answer the question: “Should I have one repository for my dbt project or many?” Alternative title: “To mono-repo or not to mono-repo, that is the question!”
Before we jump into specific structures, I want to start by emphasizing that our guiding principle has always been that simpler is better, especially when you are getting started! It should also be noted that everything presented below builds upon Jeremy’s excellent write up on this from a few years back. That is the prerequisite to this article.
Before we get started, we need to take inventory. Consider the workflow and teams that will be using dbt.
From a workflow perspective, consider:
- What will the review process look like at your organization?
- Who can approve pull requests?
- Who will be able to merge code to production?
- For more complex environments who have a dev/qa/prod git branching paradigm:
- Who has access to the objects created in the dev environment? In the qa environment?
- Who needs to be alerted when code has been released to the qa branch?
- Who is responsible for promoting objects from dev to qa? From qa to prod?
From a people or team perspective, consider:
-
How do teams using dbt usually work together?
-
Do those teams have different code styles, review processes, and chief maintainers?
-
Do the teams using dbt ever use the same data sources? Is the raw data located somewhere that all teams using dbt will have access to?
-
Is there SQL that one team should have access to but another team should not? Can folks see the SQL behind the object creation?
-
Are there objects that one team is responsible for that other teams are the consumers of?
The answers to these questions should help you navigate through the four options detailed below. I also want to make it clear: the options I’m about to show you will likely be influenced by your data team(s) size but that should not be the only factor to consider. I have seen a team of 30 folks use option 1 and a team of 10 use option 3. It is truly dependent on what your priorities lay.
Note: One repository in this context equates to one dbt project with one dbt_project.yml. It does not need to have a 1:1 relationship with a dbt cloud project.
Option 1: One Repository
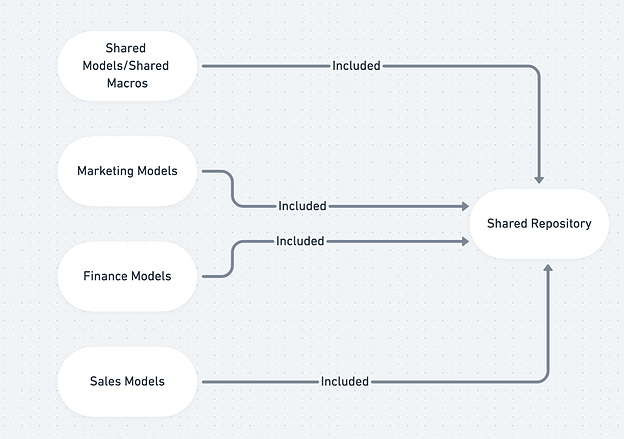
This is the most common structure we see for dbt repository configuration. Though the illustration separates models by business unit, all of the SQL files are stored and organized in a single repository.
Strengths
- Easy to share and maintain the same core business logic
- Full dependency lineage - your dbt generated DAG encompasses all of your data transformations for your entire company
Weaknesses
- Too many people! Your repository could have a lot of concurrently open issues/pull requests.
- Too many models! Your analyst is now wading through hundreds of files when their team only works on one business unit’s modeling
- Pull Request approval can be challenging (who has approval for which team? who approves changes to core models used across teams?)
This is our most time tested option and our most recommended. However, we have started to see folks “size out” of this approach. While it’s difficult to define qualitatively when your team has outgrown this model, these are some factors to consider that might push you to consider alternative options:
- Your project has 500+ models and the time it takes to compile your dbt project hinders the workflow of your developer*
- Your git workflow is starting to become cumbersome because there are too many hands in the pot in terms of who needs to approve what
*We are making significant efforts to improve this on larger projects but this is something to keep in mind.
Option 2: Separate Team Repository with One Shared Repository

This is one of the first structures we see people move toward when they “outgrow” the mono repo: there is one “core” repository that is incorporated into team specific repositories as a package. If you aren’t familiar with packages, see the documentation for more information.
How would the above function? While each team would work in their own repository, they would put shared items into the shared repository which is then installed in as a package to their repository. Some common things to put into that shared repository would be:
- a core
dim_customersmodel that is relevant across marketing and finance departments. all_daysor calendar model that defines your specific business logics around your financial year calendar and company holidays.- Macros to be used across your business units. Things like date conversions, seed files to help segment company wide attributes, etc.
- Shared sources (sources.yml files + staging models for those sources)
What doesn’t go into that shared repository?
- Models specific to the team (things like
fct_transactionsorfct_ads) would live in the unique team repos. - Team specific logic (things like if you have different definitions of what revenue is, etc)
Strengths
- Easier approval workflows in terms of team-specific models
- Easier to control user permissions (especially if you have sensitive data or SQL)
- Fewer people contributing to each repository
Weaknesses
- Hard to decide what goes into the Shared Repository
- Maintaining downstream dependencies of macros and models. There is a need to create a CI/CD process that assures changes in the shared repository will not negatively impact the downstream repositories. It’s possible that you will have to introduce semantic versioning to mitigate miscommunication about breaking changes.
- Incomplete lineage/documentation for objects not the shared repository
This is the option I recommend the most when one must stray away from Option 2. This follows our dbt viewpoint the best in terms of dry code and collaboration as opposed to Option 3 & 4.
Option 3: Completely Separate Repositories

Then, there is the “don’t allow any overlap” complete separation of repositories within a single organization.
Strengths
- Simple approval process
- Fitting if different teams have separate Snowflake Accounts/Redshift instances
Weaknesses
- Easy to create duplicate business logic or out of sync business logic between repositories
- A less than ideal work around: consumers from other teams can subscribe to another team’s releases to be aware of changes.
- Non-collaborative approach
- Incomplete lineage/documentation of company wide data transformations
There is a time and a place where this makes sense but you start to lose the reusability of code that is one of dbt’s biggest strengths! Unless there is a really good security reason behind this and a true separation of analytics needs across the teams, this approach is the one we recommend avoiding as much as possible.
Option 4: Separate Team Repositories + One Documentation Repository
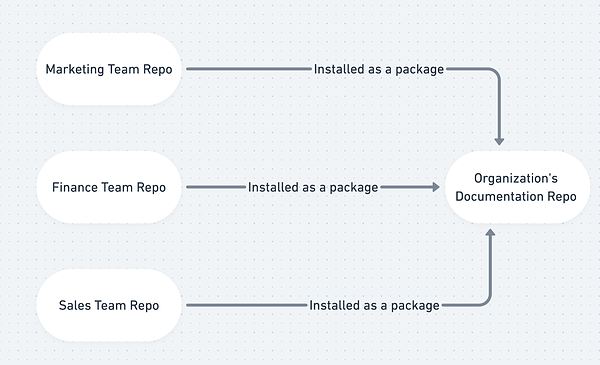
This approach is nearly identical to the former (completely separate repositories) but solves one of the weaknesses (“incomplete lineage/documentation”) by introducing an additional repository. If you need something akin to Option 3, this is the better approach.
Strengths
- Creates a project to provide an overview of the entire organization’s dbt projects*
- Simple maintenance
- Takes advantage of the strengths from
completely separate repositories(see above example)
Weaknesses
- Creates an extraneous project for administrative oversight
- Does not prevent conflicting business logic or duplicate macros
- All models must have unique names across all packages
** The project will include the information from the dbt projects but might be missing information that is pulled from your data warehouse if you are on multiple Snowflake accounts/Redshift instances. This is because dbt is only able to query the information schema from that one connection.
So… to mono-repo or not to mono-repo?
All of the above configurations “work”. And as detailed, they each solve for a different use case and business priority. At the end of the day, you need to choose what makes sense for your team today and what your team will need 6 months from now. My recommendations are:
- Ask the above questions.
- Figure out what may be a pain point in the future and try to plan for it from the beginning.
- Don’t over-complicate things until you have the right reason. As I said in my Coalesce talk: don’t drag your skeletons from one closet to another 💀!
Note: Our attempt in writing guides like this and How we structure our dbt projects aren’t to try to convince you that our way is right; it is to hopefully save you the hundreds of hours it has taken us to form those opinions!
Comments